
FAFNet: Fully-Aligned Fusion Network for RGBD Semantic Segmentation based on Hierarchical Semantic Flows
Published in IET Image Processing, 2022
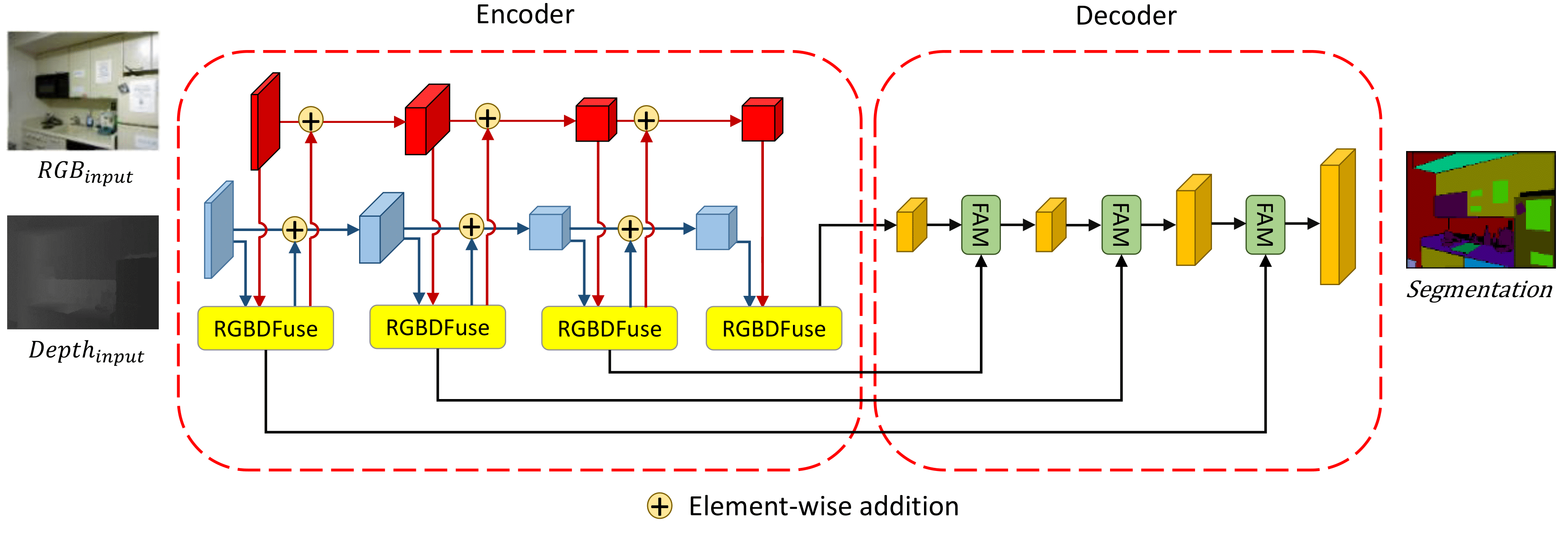
Figure 1: Overview of our FAFNet. It is based on the encoder-decoder structure. The inputs of our network are two images representing color and depth respectively. Each pair of images is processed by RGBDFuse block and sent back to the backbone to fuse with original color and depth features. The copy of each RGBDFuse block will be propagated to the corresponding layer of decoder to align with high-level features.
Abstract: Depth maps are acquirable and irreplaceable geometric information that significantly enhances traditional color images. RGB and Depth (RGBD) images have been widely used in various image analysis applications, but they are still very limited due to challenges from different modalities and misalignment between color and depth. In this paper, we present a Fully-Aligned Fusion Network (FAFNet) for RGBD semantic segmentation. To improve cross-modality fusion, a new RGBD fusion block is proposed, features from color images and depth maps are first fused by an attention cross fusion module and then aligned by a semantic flow. A multi-layer structure is also designed to hierarchically utilize our RGBD fusion block, which not only eases issues of low resolution and noises for depth maps but also reduces the loss of semantic features in the upsampling process. Quantitative and qualitative evaluations on both the NYU-Depth V2 and the SUN RGB-D dataset demonstrate that our FAFNet model outperforms state-of-the-art RGBD semantic segmentation methods.
Codes: https://github.com/CaliforniaChen/FAFNet.
Recommended citation: Jiazhou Chen, Yangfan Zhan, Yanghui Xu, Xiang Pan*. " FAFNet: Fully-Aligned Fusion Network for RGBD Semantic Segmentation based on Hierarchical Semantic Flows." IET Image Processing. 2022.